When reading poetry, it feels as if you are reading emotion. A good poet can use words to bring to their reader whichever emotions they choose. To do this, these poets often have to look deep within themselves, using their own lives as fuel. For this reason you would expect that poets and as a result, their poetry, would be influenced by the events happening around them. If certain events caused the poet’s view of the world to be an unhappy one, you’d expect their poetry to be unhappy, and of course the same for the opposite.
In this analysis I attempt to show this relation between world events and the poets of those times.
Gathering the required data – this being poems and their dates – proved to be a very difficult task. I had initially hoped to be able to show an analysis of the entire 20th century (this may still happen when I find more time and/or sources), but in the end I settled for the years between 1890 - 1925. I managed to collect an overall number of 97 poems (a few of which are excluded from the analysis due to being written in 1888 or 1889) from 6 of the most well known poets of the time. These poets being:
- William Yeats
- T. S. Eliot
- Robert Frost
- Wallace Stevens
- E. E. Cummings
- D. H. Lawrence
I will only be going through the preparation code for Yeats. The rest is similar but not exactly the same, and can be found in my github repository (https://github.com/Laurence-Sonnenberg/single_word_poetry_analysis) if anyone would like to re-create anything I have done. The actual analysis is done using all poets/poems combined.
Firstly I load the packages I’m going to need. I have included a small function that other people might find useful.
load_pkg <- function(packagelist) {
# Check if any package needs installation:
PackagesNeedingInstall <- packagelist[!(packagelist %in% installed.packages()[,"Package"])]
if(length(PackagesNeedingInstall))
{
cat("\nInstalling necesarry packages: ", paste0(PackagesNeedingInstall,collapse = ", "), "\n")
install.packages(PackagesNeedingInstall, dependencies = T, repos = "http://cran-mirror.cs.uu.nl/")
}
# load packages into R:
x <- suppressWarnings(lapply(packagelist,
require, character.only = TRUE, quietly = T))
}
pkg_list <- c("tidyverse",
"tidytext",
"stringr",
"rvest",
"lubridate",
"purrr")
load_pkg(pkg_list)##
## Installing necesarry packages: tidytextThe website I use for scraping has a page for each poet which lists the poems available – then it has a seperate page for each of the poems in the list, along with their dates. I have chosen this website specifically because having each poem dated is a must for my analysis. I run an initial scrape using rvest to get the names which are then cleaned so they can be used in the urls to get the poems and dates. Some names are not exactly the same as their url versions, so they need to be manually changed.
# page url
poemNameUrl <- "http://www.poetry-archive.com/y/yeats_w_b.html"
# scrape for poem names
poemName <- poemNameUrl %>%
read_html() %>%
html_nodes("a font") %>%
html_text()
# clean names
poemName <- poemName[1:50] %>%
str_replace_all(pattern = "\r", replacement = "") %>%
str_replace_all(pattern = "\n", replacement = " ") %>%
str_replace_all(pattern = "[ ]{2}", replacement = "") %>%
str_replace_all(pattern = "[[:punct:]]", replacement = "") %>%
tolower()
# hardcode 2 poem names to fit in with used url name
poemName[9] <- "he mourns for the change"
poemName[24] <- "the old men admiring themselves"
# display
head(poemName, 10)## [1] "at galway races" "the blessed"
## [3] "the cap and bells" "the cat and the moon"
## [5] "down by the salley gardens" "dream of a blessed spirit"
## [7] "the falling of the leaves" "he bids his beloved be at peace"
## [9] "he mourns for the change" "he remembers forgotten beauty"Next I need to scrape the website for the poems and their dates. To do this I use a function that takes a poem name – and again using rvest – scrapes for the given poem and its date, then cleans the text and waits before returning. The wait is so that I don’t send too many requests to the website in quick succession.
# function to scrape for poem and its date using poem names
GetPoemAndDate <- function(poemName) {
# split string at empty space and unlist the result
nameVec <- unlist(str_split(poemName, pattern = " "))
# use result in url
url <- str_c("http://www.poetry-archive.com/y/",
paste(nameVec, collapse = "_"),
".html")
# scrape for poem and clean
poem <- url %>%
read_html() %>%
html_nodes("dl") %>%
html_text() %>%
str_replace_all(pattern = "\r", replacement = "") %>%
str_replace_all(pattern = "\n", replacement = " ") %>%
str_replace_all(pattern = "[ ]{2}", replacement = "")
# scrape for date
date <- url %>%
read_html() %>%
html_nodes("td font") %>%
html_text()
# clean dates
date <- date[3] %>%
str_extract(pattern = "[0-9]+")
# pause before function return
Sys.sleep(runif(1, 0, 1))
return(list(poem = poem, date = date))
}I then use the previous function in a for loop which loops through each poems name and scrapes for that particular poem and its date. With each loop I also add the data frame of poem and date to a list. Once the for loop has completed I rbind all the data frames together. A complete data frame of all poems and dates will be needed for the next step.
# get poems and dates
poemDataFrame <- list()
count <- 1
for (name in poemName) {
# get poem and date for given poem name
poemNameDate <- GetPoemAndDate(name)
# create data frame of name and date and add it to list
poemDataFrame[[count]] <- data.frame(poem = poemNameDate$poem,
date = poemNameDate$date,
stringsAsFactors = FALSE)
count <- count + 1
}
# rbind all poems and dates
poemDataFrame <- do.call(rbind, poemDataFrame)I then combine the names from the original scrape, the dates, and the poems into a single data frame so they will be ready for me to work with. I also take a look at all the text, checking for and correcting any errors that could negatively affect my analysis. In this case I have found an error in a date.
# create data frame of names, poems and dates
poemDataFrame <- cbind(poemName, poemDataFrame)
# hardcode single date with error
poemDataFrame$date[40] <- "1916"After this, we have a dataset of dimension 50x3 with column headings poemName, poem and date.
The next function I have written takes a row index, and using the combined data frame of poems, names and dates, along with tidytext, tokenizes the poem found at that index into single words. It then uses anti_join from dplyr, along with the stop_words dataset from tidytext, to create a tibble – this tibble will now be missing a list of stop words which will not be helpful in the analysis. This list of words for each poem is then used to create a sentiment score. This is done using inner_join and the sentiment dataset filtered on the bing lexicon, again from tidytext. The function calculates the sentiment score value for the poem depending on the number of negative and positive words in the list – negative words get a value of -1 and positive get a value of 1, these values are then summed and the result returned as a percentage of the number of words in that particular poem.
# function to analyse poems and return scores using bing lexicon
bingAnalysePoems <- function(i) {
# get poem a index i
poem <- data_frame(poem = poemDataFrame$poem[i])
# tokenize into words
textTokenized <- poem %>%
unnest_tokens(word, poem)
# load stop words dataset
data("stop_words")
# anti join on stop words
tidyPoem <- textTokenized %>%
anti_join(stop_words)
# filter on bing lexicon
bing <- sentiments %>%
filter(lexicon == "bing") %>%
select(-score)
# join on bing to get whether words are positive or negative
poemSentiment <- tidyPoem %>%
inner_join(bing)
# get score for poem
poemSentiment <- poemSentiment %>%
mutate(score = ifelse(poemSentiment$sentiment == "positive", 1, -1))
# get score as a percentage of total words in poem
finalScore <- (sum(poemSentiment$score)/length(textTokenized$word))*10
return(finalScore)
}Now, using the previous function and sapply I get the score for each poem and create a data frame with the poems score and its date. These scores will be used later to show the change in sentiment for each year.
# get scores
scores <- sapply(1:length(poemDataFrame$poem), bingAnalysePoems)
# create data frame with data and scores
dateAndScore <- data.frame(scores) %>%
mutate(date = year(ymd(str_c(poemDataFrame$date, "/01/01"))))
# display
head(dateAndScore, 10)## scores date
## 1 -0.20618557 1910
## 2 -0.03649635 1899
## 3 0.16528926 1899
## 4 -0.13157895 1919
## 5 0.32258065 1921
## 6 0.31250000 1921
## 7 -0.42253521 1889
## 8 -0.73394495 1899
## 9 -0.23255814 1899
## 10 -0.44025157 1899The next function I have written takes a particular sentiment, which in this case can also be called an emotion, from a number of sentiments found in the NRC lexicon of the sentiment dataset; it then again creates a tibble of words not including the stop words, and using semi_join and the sentiment dataset filtered on the NRC lexicon and the particular sentiment given, returns the sum of the number of words relating to that sentiment. These sums will be used to show which emotions were high (or low) in a particular year.
# NRC analysis function
nrcAnalysePoems <- function(sent) {
# nrcPoem used from global environment
textTokenized <- nrcPoem %>%
unnest_tokens(word, poem)
# load stop words dataset
data("stop_words")
tidyPoem <- textTokenized %>%
anti_join(stop_words)
# filter on NRC lexicon and sentiment
nrcSentiment <- sentiments %>%
filter(lexicon == "nrc", sentiment == sent)
# join on sentiment and count words
sentimentInPoem <- tidyPoem %>%
semi_join(nrcSentiment) %>%
count(word, sort = TRUE)
# return the sum of the counted words
return(sum(sentimentInPoem$n))
}Using the above function and sapply, I get the sums for each different sentiment in my sentiments list; this is done within a for loop, which loops through each poem, creating a data frame with each row consisting of a sentiment, the sum of words for that sentiment, the name of the poem the sentiment relates to, and the poems date. I then add this data frame to a list which will be used in my next step.
# list of used setiments found in NRC lexicon
sentimentsVec <- c("anger", "anticipation", "disgust", "fear",
"joy","sadness", "surprise", "trust")
# create empty list
nrcAnalysisDataFrame <- list()
# get a frequency percetage for each sentiment found in the NRC lexicon
for (i in 1:length(poemDataFrame$poem)) {
# poem at index i - to be used in nrcAnalysePoems function environment
nrcPoem <- data_frame(poem = poemDataFrame$poem[i])
# create data frame for each poem of all sentiment sums
nrcDataFrame <- as.data.frame(sapply(sentimentsVec, nrcAnalysePoems)) %>%
rownames_to_column() %>%
select(sentiment = rowname, value = 2) %>%
mutate(name = poemDataFrame$poemName[i],
date = poemDataFrame$date[i])
# add data frame to list
nrcAnalysisDataFrame[[i]] <- nrcDataFrame
}Once the for loop has completed I rbind all the data frames in the list so that I can work with all of them together as a whole.
# rbind list of all NRC sum values for all poems
nrcAnalysisDataFrame <- do.call(rbind, nrcAnalysisDataFrame)
# display
head(nrcAnalysisDataFrame, 10)## sentiment value name date
## 1 anger 1 at galway races 1910
## 2 anticipation 4 at galway races 1910
## 3 disgust 2 at galway races 1910
## 4 fear 4 at galway races 1910
## 5 joy 2 at galway races 1910
## 6 sadness 4 at galway races 1910
## 7 surprise 2 at galway races 1910
## 8 trust 2 at galway races 1910
## 9 anger 0 the blessed 1899
## 10 anticipation 9 the blessed 1899Now all the preparation code is done and we are ready to begin analyzing. For ease of use I have created a function for each poet to run all the code shown previously; the functions return both the bing and the NRC data frames, ready to be used. These functions are run but will not be shown here.
Firstly I will need to call each poet’s function and assign the returned data frames to variables so that I can work with them as needed.
yeats <- Yeats()
eliot <- Eliot()
frost <- Frost()
wallace <- Wallace()
cummings <- Cummings()
lawrence <- Lawrence()
poets <- list(yeats, eliot, frost, wallace, cummings, lawrence)Having collected all the poems from our five poets, we plot the count of poems per year for each of our selected sample:
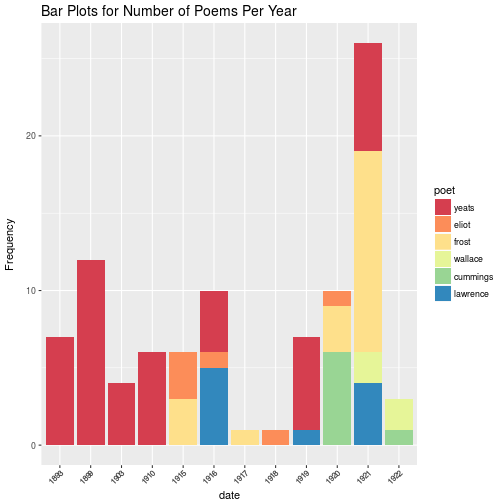
From this we see that Yeats dominates the earlier period in our sample, while Frost plays a large part in the second half of the sample of text.
Next I will join all the bing scores for all poems using rbind, I do this so that I can work with all the data at once. I then group by date and get a mean score for each year in the complete data frame. This returns a tibble of scores and dates which I can now plot.
# rbind data frames and summarize
completedataFramebing <- poets %>%
map(~.x %>% .[[1]] %>% data.frame) %>%
reduce(rbind) %>%
filter(date >= 1890) %>%
group_by(date) %>%
summarize(score = mean(scores))
# display
head(completedataFramebing, 10)## # A tibble: 10 × 2
## date score
## <dbl> <dbl>
## 1 1893 -0.23988213
## 2 1899 -0.31855413
## 3 1903 -0.03143456
## 4 1910 -0.09117054
## 5 1915 -0.20194924
## 6 1916 -0.29473096
## 7 1917 -0.57692308
## 8 1918 -0.50458716
## 9 1919 -0.16981618
## 10 1920 -0.14955234I use multiplot so that I can show two different plots side by side.
# plot bar plot
p1 <- ggplot(data = completedataFramebing) +
geom_bar(aes(x = date, y = score, fill = score),
stat = "identity", position = "identity") +
ylim(-1, 1) +
ylab("mean percentage score") +
xlab("year") +
theme(legend.key.size = unit(0.5, "cm"),
legend.text = element_text(size = 7),
legend.position = c(0.87, 0.77)) +
ggtitle("Bar Plot of Percentage Scores") +
theme(plot.title = element_text(size = 12))
# plot dot and line plot
p2 <- ggplot(data = completedataFramebing) +
geom_line(aes(x = date, y = score), colour = "blue") +
geom_point(aes(x = date, y = score), size = 1.3, colour = "blue") +
ylim(-1, 1) +
ylab("mean percentage score") +
xlab("year") +
ggtitle("Dot and Line Plot of Percentage Scores") +
theme(plot.title = element_text(size = 12))
# use multiplot function
# can be found at http://www.cookbook-r.com/Graphs/Multiple_graphs_on_one_page_(ggplot2)/
multiplot(p1, p2, cols = 2)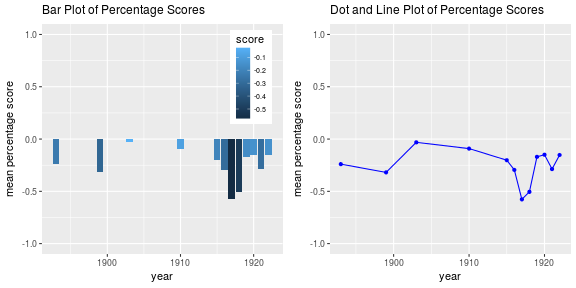
The 0 values in the bar plot are not all actual 0 values but rather years where no information is available. When looking at the plots we can see a steady decline between the period 1890 - 1900, then due to a lack of data very little can be seen during the period from 1900 - 1915, after which there is again a massive decline between 1915 and 1920 and again a small drop between 1920 and 1925.
We can also look at the individuals poets, to determine who of them portrayed their sorrow the most through their poems. To do this we plot the average score per poet.
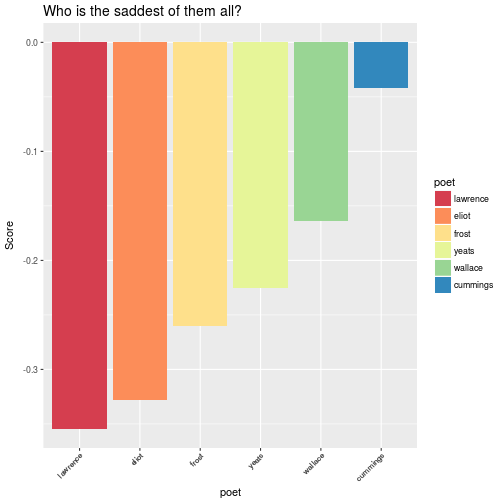
From the plot we see that Lawrence has the most negative mean score and with poems such as giorno dei morti or day of the dead, it comes as no suprise!
Finally, let’s do the NRC analysis. Firstly, I join together all the poet’s NRC data frames using rbind, again so I can work with all the data at once. I then group them by date and sentiment, sum the sentiment values for each poem and use this sum to get percentage values for each sentiment in each year. Once I have done this the data frame is ready to be plotted.
# rbind data frames and summarize
yeatsnrc <-
poets %>%
map(~.x %>% .[[2]]) %>%
reduce(rbind) %>%
filter(date >= 1890) %>%
group_by(date, sentiment) %>%
summarise(dateSum = sum(value)) %>%
mutate(dateFreqPerc = dateSum/sum(dateSum))
head(yeatsnrc, 10)## Source: local data frame [10 x 4]
## Groups: date [2]
##
## date sentiment dateSum dateFreqPerc
## <chr> <chr> <int> <dbl>
## 1 1893 anger 25 0.10775862
## 2 1893 anticipation 38 0.16379310
## 3 1893 disgust 11 0.04741379
## 4 1893 fear 38 0.16379310
## 5 1893 joy 42 0.18103448
## 6 1893 sadness 34 0.14655172
## 7 1893 surprise 8 0.03448276
## 8 1893 trust 36 0.15517241
## 9 1899 anger 17 0.06390977
## 10 1899 anticipation 46 0.17293233I use facet_wrap on the date so that I can display all the plots for all the years at once.
# plot multiple NRC barplots using facet wrap
ggplot(data = yeatsnrc, aes(x = sentiment,
y = dateFreqPerc,
fill = sentiment)) +
geom_bar(stat = "identity") +
scale_fill_brewer(palette = "Spectral") +
guides(fill = FALSE) +
facet_wrap(~date, ncol = 2) +
theme(axis.text.x = element_text(
angle = 45,
hjust = 1,
size = 8)) +
theme(axis.title.y = element_text(margin = margin(0, 10, 0, 0))) +
ylab("frequency percentage") +
ggtitle("Bar Plots for Sentiment Percentages Per Year") +
theme(plot.title = element_text(size = 14))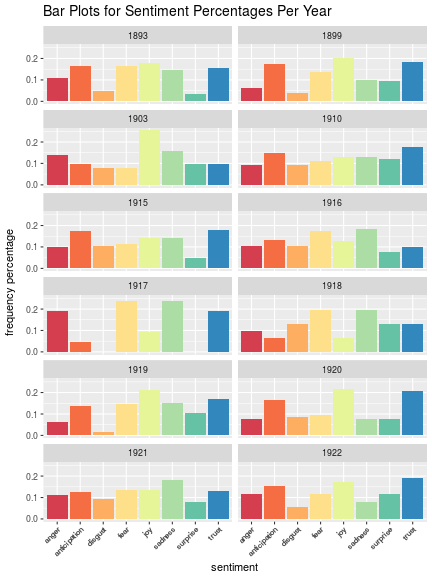
Looking at these plots we can see how sentiment changes through the years of available data. During the early 1890s we see equal percentages of anticipation, fear, joy, sadness and trust, while later we see anticipation, joy and trust. In 1903 joy takes the lead, but in 1910 and 1915 we see anticipation and trust increasing with fear and joy equal. In 1916 fear and sadness are high and 1917 anger, fear, sadness and trust are notibly high. From 1918 - 1919 we see a change from negative to positive with joy taking a big lead in 1919 and again in 1920. 1921 sees sadness again with others coming in with mostly equal percentages, and 1922 anticipation, joy and trust.
I am not a historian but fortunately my sister majored in history, so I asked her to send me a timeline of influencial world events between the years this analysis is based on. I have used this timeline to explain the findings.
From both the bing and NRC analysis it can be seen that there was a very apparent negative trend during the years from 1915 - 1920, this is very possibly due to a number of world events, namely; World War I during the years from 1914 - 1918, the influenza pandemic which lasted from 1918 - 1919, and the Russian Revolution in 1917. Another negative trend seems to appear at the end of the 19th Century, this time it is possibly due to the Boer War, which lasted from 1899 - 1902 and had repurcussions across Europe, as well as the Indian famine which killed an estimated one million people during the years 1899 and 1900.
A few things to be mentioned:
- As we all know the pop artists of the time will always move with popular trends, so it could be that the poets chosen, being the most popular during the years this analysis is based on, may have been more likely to be influenced by the events around them
- Due to the surprisingly difficult task of finding poetry with enough information, this analysis has been based on only a small number of poems
Taking the above into account, it is clear more work needs to be done; though the findings from this brief analysis do show a possible relation between poetry and the events of the time.